
Christyan Jean-Charles
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pandas_datareader as pdr
import seaborn as sns
1. Summary:
In this repo, I ciphered through dictionaries with positive and negative sentiments as well as created my three own variables to measure the sentiment of S&P 500 firm 10-K’s. Using these sentiment variables, I went through the data to find out the correlation between sentiment analysis and stock returns. I conducted a cross-sectional study to find out if positive or negative sentiments within 10-K filings have an effect on returns. With a wide variety of industries within the data sample, it was interesting to see to what extent the sentiment of each companies’ 10-K correlated with the cumulative returns of each stock. I wanted to see the true importance of the sentiment of 10-K filings and whether they had a real impact on returns.
Throughout this repo, I found myself re-evaluating the 10-K’s based on their sentiment. I attempted to create a conclusive list that would give me a good basis to determine the sentiment score of each firm’s 10-K. I found that while the LM_dictionary proved to have no real correlation, the ML_dictionary showed a slight positive trend between sentiment and returns. With my hand-made sentiments I found some interesting trends that I will share towards the latter half of this file.
2. Data Section:
The sample data consists of S&P 500 firms as well as their returns. The return variables were based around two variables one which consider the filing date plus two days which were inclusive, as well as the filing date plus 3 days to the filing date plus 10 days.
Sample Data:
sample_df = pd.read_csv('output/analysis_sample.csv')
sample_df
| Symbol | Security | GICS Sector | GICS Sub-Industry | Headquarters Location | Date added | CIK | Founded | LM_pos_score | LM_neg_score | ... | mb | prof_a | ppe_a | cash_a | xrd_a | dltt_a | invopps_FG09 | sales_g | dv_a | short_debt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | MMM | 3M | Industrials | Industrial Conglomerates | Saint Paul, Minnesota | 1957-03-04 | 66740 | 1902 | 0.003977 | 0.023249 | ... | 2.838265 | 0.197931 | 0.218538 | 0.101228 | 0.042361 | 0.355625 | 2.564301 | 0.098527 | 0.072655 | 0.086095 |
| 1 | AOS | A. O. Smith | Industrials | Building Products | Milwaukee, Wisconsin | 2017-07-26 | 91142 | 1916 | 0.003756 | 0.012984 | ... | 4.368153 | 0.197847 | 0.183974 | 0.181729 | 0.027113 | 0.061075 | NaN | 0.222291 | 0.048958 | 0.080191 |
| 2 | ABT | Abbott | Health Care | Health Care Equipment | North Chicago, Illinois | 1957-03-04 | 1800 | 1888 | 0.003726 | 0.012793 | ... | 3.825614 | 0.166285 | 0.134475 | 0.136297 | 0.036465 | 0.242726 | 3.559664 | 0.244654 | 0.042582 | 0.051893 |
| 3 | ABBV | AbbVie | Health Care | Pharmaceuticals | North Chicago, Illinois | 2012-12-31 | 1551152 | 2013 (1888) | 0.006481 | 0.015448 | ... | 2.528878 | 0.194433 | 0.040074 | 0.067086 | 0.054911 | 0.442929 | 2.144449 | 0.227438 | 0.063203 | 0.163364 |
| 4 | ACN | Accenture | Information Technology | IT Consulting & Other Services | Dublin, Ireland | 2011-07-06 | 1467373 | 1989 | 0.008642 | 0.016861 | ... | 5.474851 | 0.195625 | 0.111674 | 0.189283 | 0.025902 | 0.063702 | 5.023477 | 0.140013 | 0.051790 | 0.215661 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 347 | XYL | Xylem Inc. | Industrials | Industrial Machinery | White Plains, New York | 2011-11-01 | 1524472 | 2011 | 0.007049 | 0.017495 | ... | 3.225061 | 0.103432 | 0.114548 | 0.163001 | 0.024650 | 0.324190 | 2.909645 | 0.065422 | 0.024529 | 0.025073 |
| 348 | YUM | Yum! Brands | Consumer Discretionary | Restaurants | Louisville, Kentucky | 1997-10-06 | 1041061 | 1997 | 0.006078 | 0.016549 | ... | 9.129993 | 0.395240 | 0.337915 | 0.123366 | 0.000000 | 1.019505 | 8.944086 | 0.164897 | 0.099229 | 0.012864 |
| 349 | ZBRA | Zebra Technologies | Information Technology | Electronic Equipment & Instruments | Lincolnshire, Illinois | 2019-12-23 | 877212 | 1969 | 0.006258 | 0.014964 | ... | 5.635335 | 0.192759 | 0.064843 | 0.055350 | 0.091231 | 0.167820 | 5.301699 | 0.265063 | 0.000000 | 0.089083 |
| 350 | ZBH | Zimmer Biomet | Health Care | Health Care Equipment | Warsaw, Indiana | 2001-08-07 | 1136869 | 1927 | 0.004591 | 0.021783 | ... | 1.592191 | 0.092759 | 0.097530 | 0.020400 | 0.021892 | 0.242318 | 1.415104 | 0.115553 | 0.008531 | 0.227553 |
| 351 | ZTS | Zoetis | Health Care | Pharmaceuticals | Parsippany, New Jersey | 2013-06-21 | 1555280 | 1952 | 0.005036 | 0.019980 | ... | 8.969729 | 0.236475 | 0.187266 | 0.250719 | 0.036547 | 0.485108 | 8.792744 | 0.164349 | 0.034101 | 0.006044 |
352 rows × 89 columns
Although in my build_sample file I opted to use strictly the returns from each firm around the filing day, I attempted to find the return variables by merging the sp500 data frame with the CRSP data frame that contained the stock returns. After merging:
- Converted filing_date to a date time
- Created a new column for the time difference in days between filing_date and date
- Filtered the data frame to include a variable for only data for t, t+1, and t+2
- Filtered the data frame to include a variable for only data for t+3 to t+10 as well
- Calculated the cumulative returns
- Attempted to merge them back within the data frame
#Convert filing_date to datetime
inner_merged['filing_date'] = pd.to_datetime(inner_merged['filing_date'])
# Create a new column for the time difference in days between filing_date and date
inner_merged['days_diff'] = (inner_merged['date'] - inner_merged['filing_date']).dt.days
# Filter the DataFrame to include a variable for only data for t, t+1, and t+2
Ret02 = inner_merged.loc[inner_merged['days_diff'].between(0, 2)]
# Filter the DataFrame to include a variable for only data for t+3 to t+10
Ret310 = inner_merged.loc[inner_merged['days_diff'].between(3, 10)]
This is where things got tricky for me as I could not figure out the best way to go about merging my two return variables back into the larger data frame.
The sentiment variables were built by turning the LM and ML text files into positive and negative list that could be interpreted by regex.
My Code to Build the Sentiment Variables:
# ML (BHR) Positive and Negative:
BHR_negative = pd.read_csv('inputs/ML_negative_unigram.txt',
names=['word'])['word'].to_list()
with open('inputs/ML_positive_unigram.txt', 'r') as file:
BHR_positive = [line.strip() for line in file]
BHR_negative_regex = ['('+'|'.join(BHR_negative)+')']
BHR_positive_regex = ['('+'|'.join(BHR_positive)+')']
# LM Positive and Negative:
LM = pd.read_csv('inputs/LM_MasterDictionary_1993-2021.csv')
LM_negative = LM.query('Negative > 0')['Word'].to_list()
LM_positive = LM.query('Positive > 0')['Word'].to_list()
LM_neg_regex = ['('+'|'.join(LM_negative)+')']
LM_pos_regex = ['('+'|'.join(LM_positive)+')']
The reason I chose to base my contextual sentiment around supply chain, R&D, and financial performance is because I felt these three components were essential to the success of many companies within the S&P 500. I wanted to see whether positive contextual sentiments of these components would also help in understanding the correlation between sentiment and returns. If these three components are as important as they are made out to be then it would only make sense for the returns to be positively correlated with better stock returns.
test_df = pd.read_csv('output/analysis_sample.csv')
final_sample = test_df[['Symbol', 'GICS Sector', 'ret', 'LM_pos_score', 'LM_neg_score', 'BHR_pos_score', 'BHR_neg_score', 'Positive_SC_score', 'Negative_SC_score', 'Positive_RD_score', 'Negative_RD_score', 'Positive_FP_score', 'Negative_FP_score', 'cash_a', 'prof_a','dv_a','capx_a','xrd_a']].reset_index(drop=True)
final_sample.to_csv('output/final_analysis.csv', index=False)
final_analysis = pd.read_csv('output/final_analysis.csv')
final_analysis.describe()
| ret | LM_pos_score | LM_neg_score | BHR_pos_score | BHR_neg_score | Positive_SC_score | Negative_SC_score | Positive_RD_score | Negative_RD_score | Positive_FP_score | Negative_FP_score | cash_a | prof_a | dv_a | capx_a | xrd_a | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 | 352.000000 |
| mean | 0.001998 | 0.005190 | 0.016126 | 0.024245 | 0.026095 | 0.004186 | 0.002663 | 0.004465 | 0.002981 | 0.011976 | 0.004936 | 0.131501 | 0.156031 | 0.023759 | 0.031429 | 0.028012 |
| std | 0.036578 | 0.001368 | 0.003386 | 0.003770 | 0.003386 | 0.001100 | 0.001040 | 0.001450 | 0.000757 | 0.002673 | 0.001235 | 0.121036 | 0.085127 | 0.026821 | 0.026099 | 0.043721 |
| min | -0.242779 | 0.000272 | 0.007327 | 0.003530 | 0.014692 | 0.001059 | 0.000000 | 0.001629 | 0.000543 | 0.004141 | 0.001184 | 0.003713 | -0.099432 | 0.000000 | 0.001387 | 0.000000 |
| 25% | -0.014722 | 0.004361 | 0.013670 | 0.022367 | 0.023993 | 0.003404 | 0.001936 | 0.003528 | 0.002447 | 0.010346 | 0.004136 | 0.043401 | 0.099332 | 0.000000 | 0.013221 | 0.000000 |
| 50% | -0.000509 | 0.005113 | 0.016010 | 0.024452 | 0.026107 | 0.004112 | 0.002529 | 0.004304 | 0.002909 | 0.011922 | 0.004873 | 0.096322 | 0.142072 | 0.017442 | 0.023601 | 0.008529 |
| 75% | 0.017986 | 0.005864 | 0.018104 | 0.026422 | 0.028141 | 0.004921 | 0.003250 | 0.005248 | 0.003447 | 0.013669 | 0.005603 | 0.171776 | 0.201154 | 0.035275 | 0.040391 | 0.040744 |
| max | 0.162141 | 0.010899 | 0.026658 | 0.037982 | 0.038030 | 0.007194 | 0.006580 | 0.012059 | 0.006560 | 0.021191 | 0.010717 | 0.607837 | 0.405925 | 0.164573 | 0.170436 | 0.295576 |
The stats for my final analysis sample show that on average, the stocks in the sample have a very small positive return. However looking at the standard deviation, the return values vary widely from the mean value. The percentiles show that 75% of the stocks in this sample were above .0180 or 1.8%.
For the most part, I believe that my contextual sentiments pass the “basic smell tests.” When looking at graphical evidence, the data from my final sample analysis shows that positive sentiments were found in industries where I most expected them. When it came to financial performance, the financial sector had the highest positive contextual sentiment score with consumer staples coming in 2nd, and the industrial sector coming in third.
# create the barplot
ax = sns.barplot(data=final_analysis, x="GICS Sector", y="Positive_FP_score", errorbar=None, saturation=.5, errcolor=".2", edgecolor=".2", width=0.5)
# adjust the x-axis labels
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
# set the figure size
sns.set(rc={'figure.figsize':(12,8)})
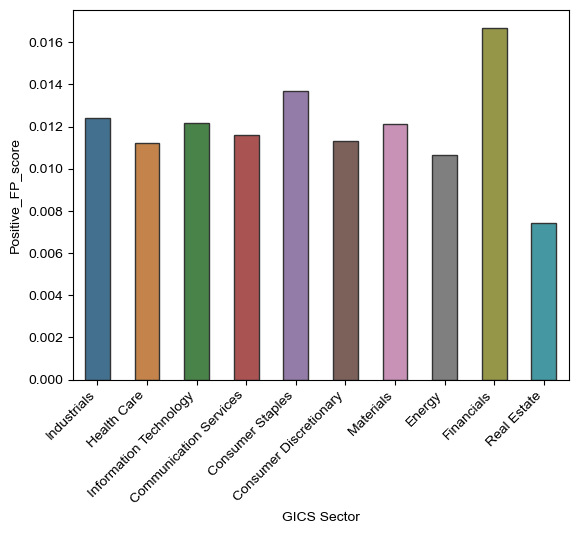
The sector with the highest positive R&D scores were the Health Care, IT, Financial, and Real Estate industries, which makes sense especially for the Health Care sector. As they are constantly under pressure to create cures and vaccines especially after the onset of COVID-19, it only makes sense that the health care sector tops the list. Same applies for the IT sector, as technology continues to evolve it would make sense for the R&D sentiment to be positive as they strive towards improving R&D to stay ahead of the curve.
# create the barplot
ax = sns.barplot(data=final_analysis, x="GICS Sector", y="Positive_RD_score", errorbar=None, saturation=.5, errcolor=".2", edgecolor=".2", width=0.5)
# adjust the x-axis labels
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
# set the figure size
sns.set(rc={'figure.figsize':(12,8)})
3. Results:
Correlation table between the return variable and the 10 sentiment measures:
sentiment_cols = ['LM_pos_score', 'LM_neg_score', 'BHR_pos_score', 'BHR_neg_score','Positive_SC_score', 'Negative_SC_score', 'Positive_RD_score','Negative_RD_score', 'Positive_FP_score', 'Negative_FP_score']
correlations = final_analysis[sentiment_cols + ['ret']].corr()['ret'].to_frame()
correlations.columns = ['correlation with ret']
correlations
| correlation with ret | |
|---|---|
| LM_pos_score | -0.090945 |
| LM_neg_score | -0.003743 |
| BHR_pos_score | 0.059411 |
| BHR_neg_score | 0.046202 |
| Positive_SC_score | -0.023058 |
| Negative_SC_score | -0.035132 |
| Positive_RD_score | -0.065353 |
| Negative_RD_score | 0.022159 |
| Positive_FP_score | 0.084587 |
| Negative_FP_score | 0.016209 |
| ret | 1.000000 |
Scatter Plot of Each Sentiment Measure Against the Return:
# Select columns of interest
sentiment_cols = ['LM_pos_score', 'LM_neg_score', 'BHR_pos_score', 'BHR_neg_score',
'Positive_SC_score', 'Negative_SC_score', 'Positive_RD_score',
'Negative_RD_score', 'Positive_FP_score', 'Negative_FP_score']
return_col = 'ret'
data = final_analysis[sentiment_cols + [return_col]]
# Create scatterplots
fig, axs = plt.subplots(nrows=5, ncols=2, figsize=(10, 20))
axs = axs.flatten()
for i, col in enumerate(sentiment_cols):
axs[i].scatter(data[col], data[return_col], alpha=0.5)
axs[i].set_xlabel(col)
axs[i].set_ylabel(return_col)
axs[i].set_title(f'{col} vs {return_col}')
plt.tight_layout()
plt.show()
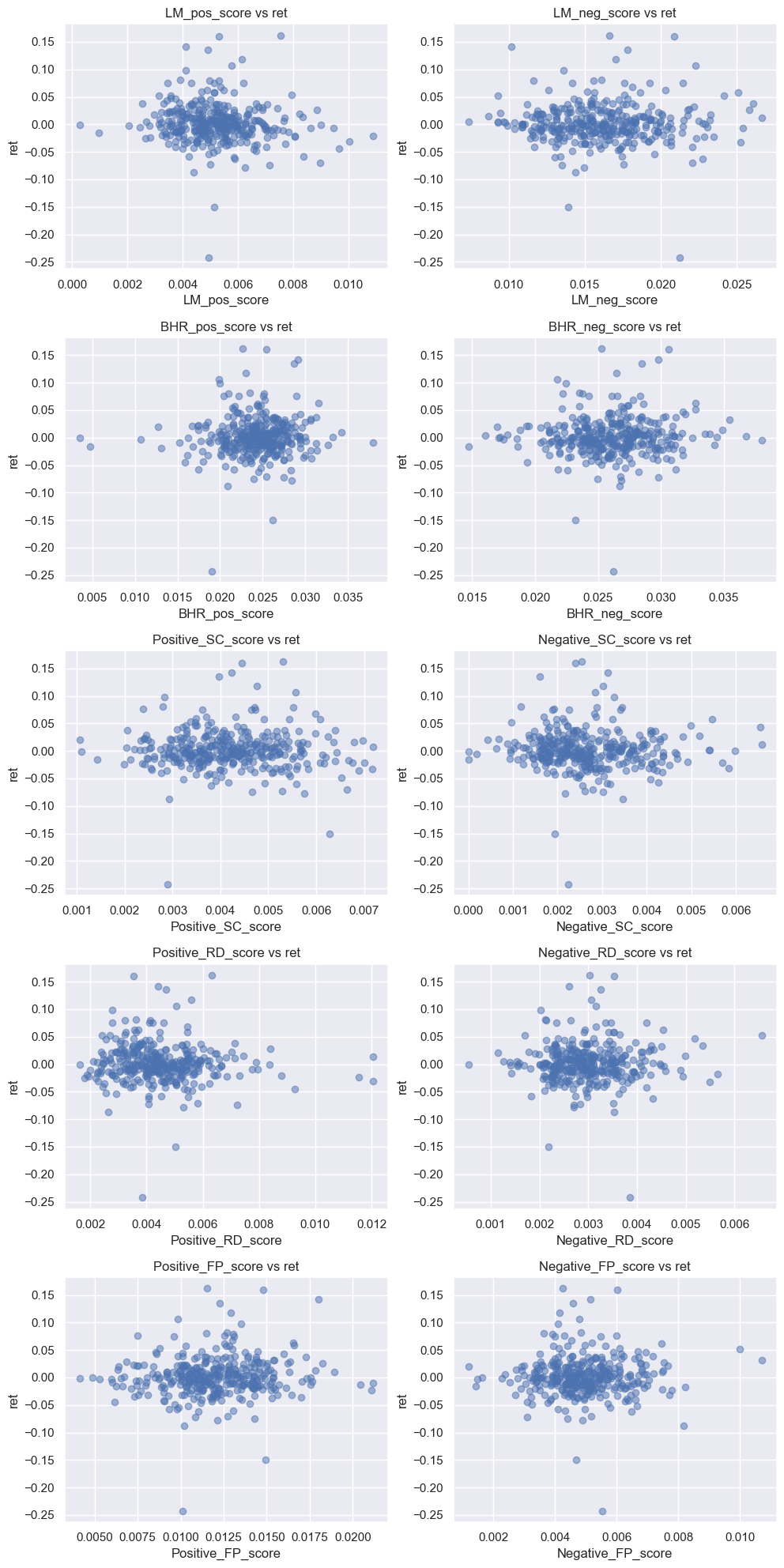
Topic 1:
When looking at the data for the return variable in comparison to the LM sentiment variables, a positive relationship can be seen. Most of the points on the graph are above 0.00 trending towards higher returns as the positive score increase. The same can be seen in greater magnitude within the ML positive sentiment. With a higher density of points falling within the upper right hand region of the graph.
The opposite is displayed for both the negative ML and LM sentiment. The magnitude of the correlation between returns and these two sentiments is relative to the positive sentiment graphs. These points lie to the left of the graph edging towards negative returns.
Overall, we can see that there is a consistent pattern in the relationship between the return variable and the four sentiment measures. Positive sentiment measures tended to show a more positive relationship with returns in comparison to the negative sentiments which showed a negative relationship with returns. However, it seems as if the ML(BHR)sentiment measures appear to have a slightly stronger relation with the return variable.
Topic 2:
I found that my data was in agreement with the Garcia, Hu, and Rohrer paper. One reason they may have included such a vast amount of data is because a relatively small sample size like mine could have led to extremities that could heavily skew the data, causing bias results. Their data encompassed many more firms, years, and additional controls which would help to decrease the amount of outliers within the data. The amount of additional firms, years, and controls could have also helped to strengthen the validity of the study. When conducting a study, such as this cross sectional event study between sentiments and stock returns, it is important to collect conclusive data that either proves or debunks your hypothesis.
Topic 3:
Unfortunately my contextual sentiments don’t look different enough in relations with my return variable. There’s no real need for further investigation as a regression line shows no trends between the contextual sentiment variables and the return variable.
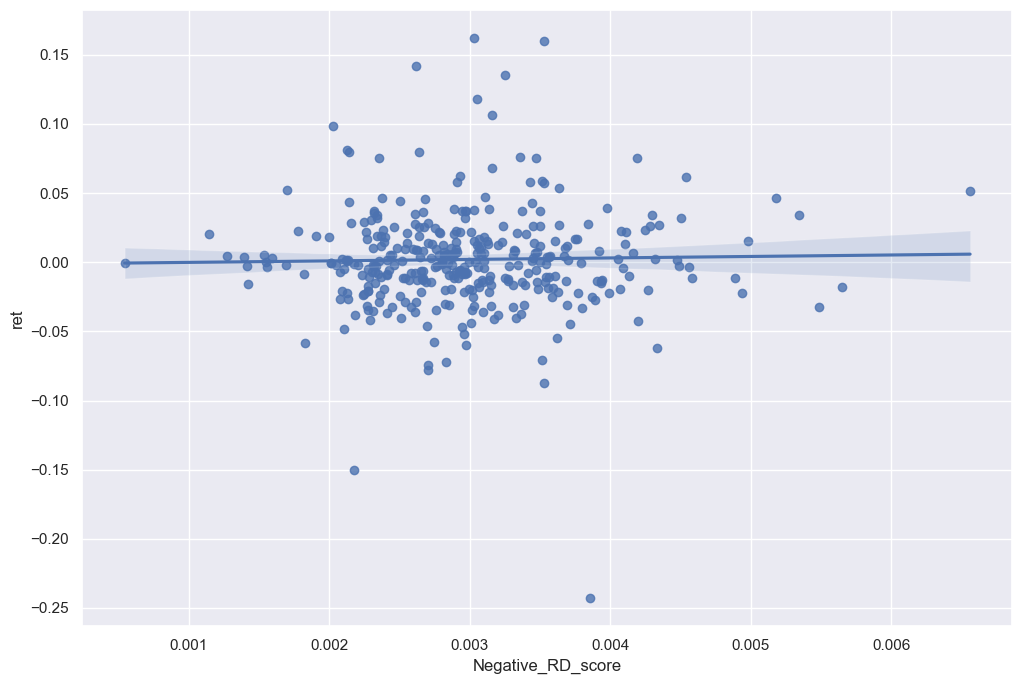
1. Negative RD Sentiment:
sns.regplot(data=final_analysis, x='Negative_RD_score', y='ret')
plt.show()
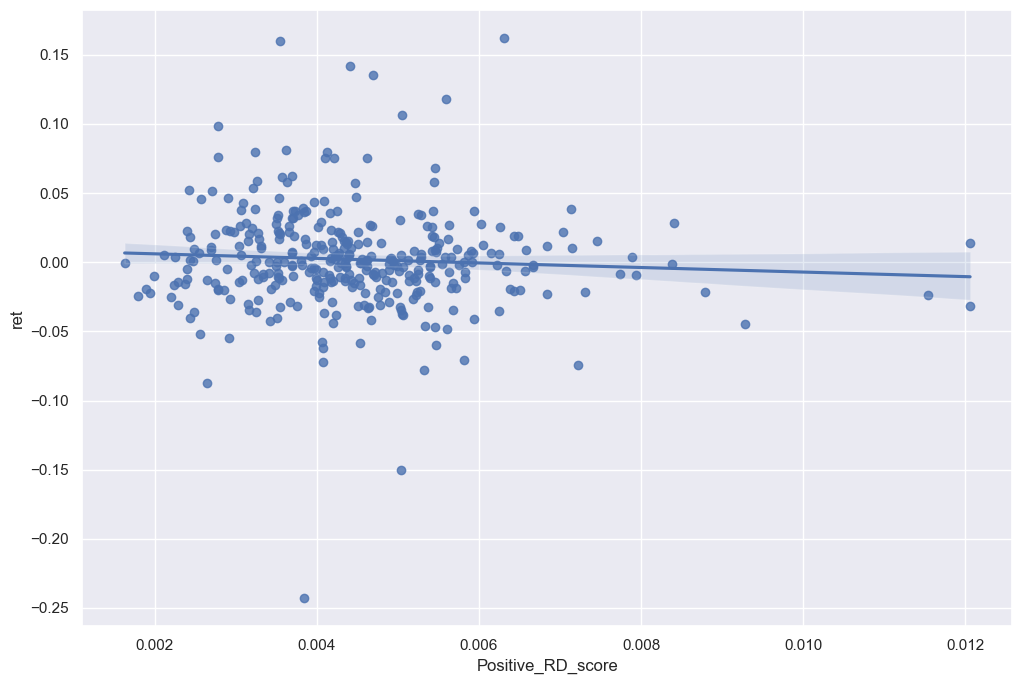
2. Positive RD Sentiment:
sns.regplot(data=final_analysis, x='Positive_RD_score', y='ret')
plt.show()
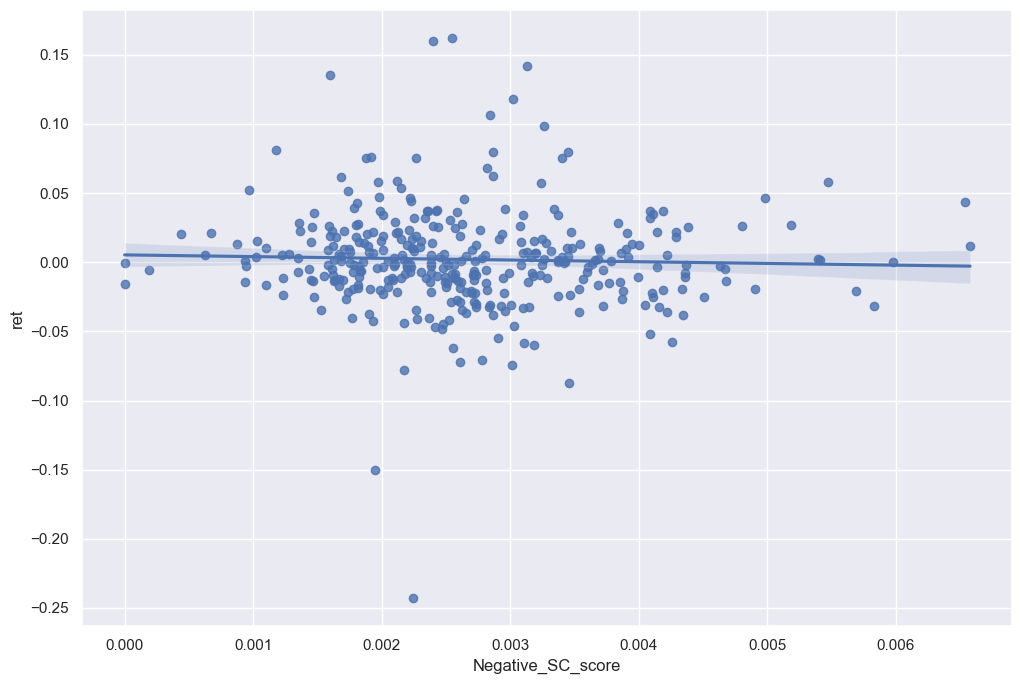
3. Negative Supply Chain Sentiment:
sns.regplot(data=final_analysis, x='Negative_SC_score', y='ret')
plt.show()
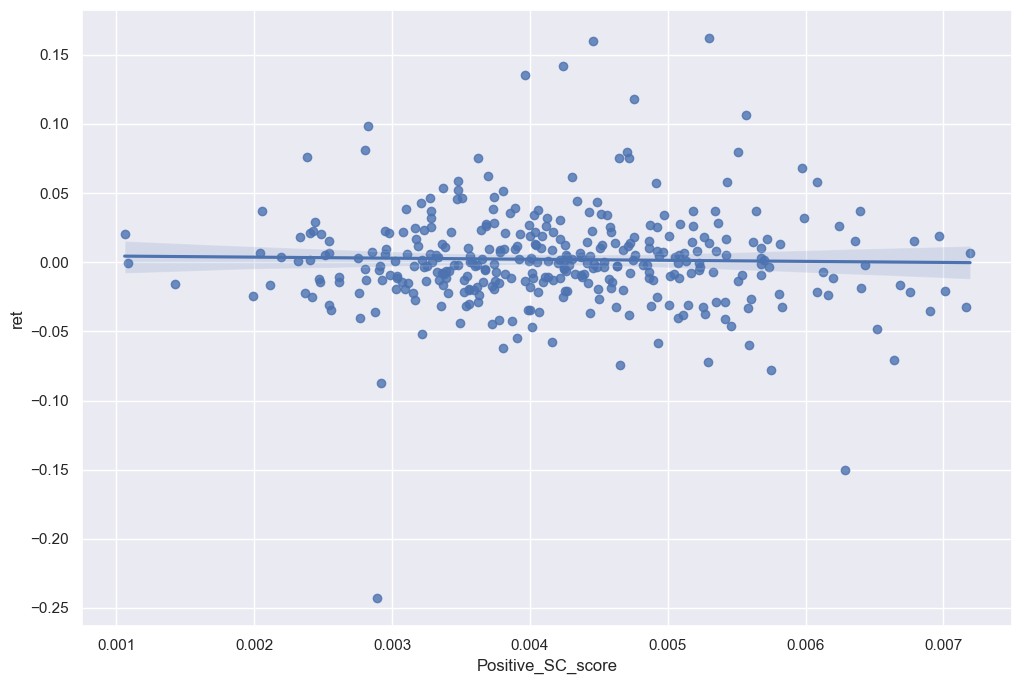
4. Positive Supply Chain Sentiment:
sns.regplot(data=final_analysis, x='Positive_SC_score', y='ret')
plt.show()
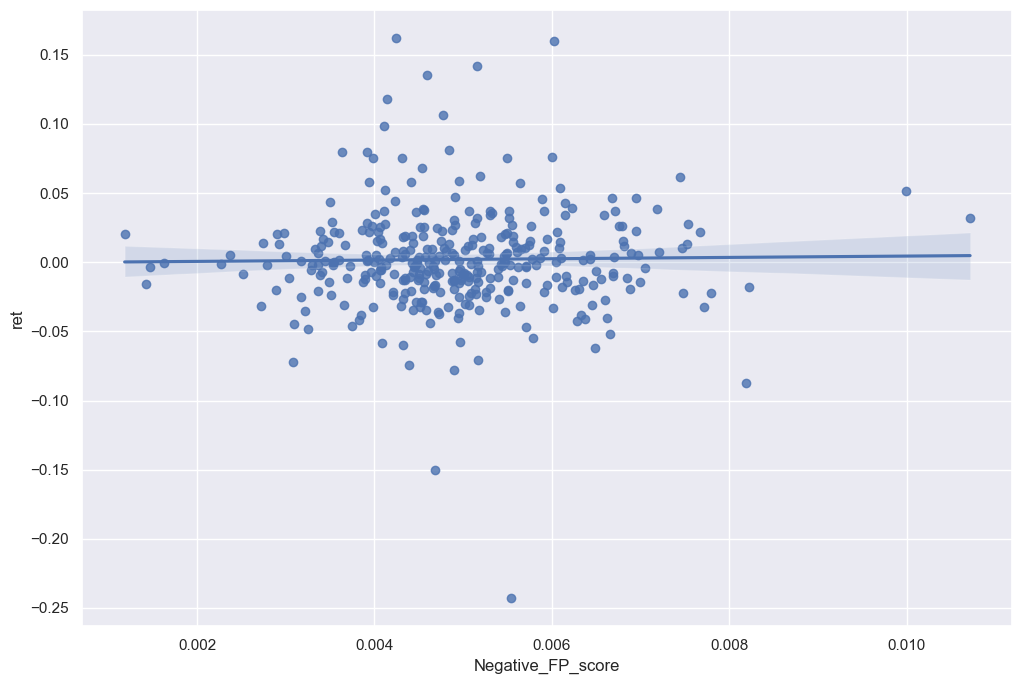
5. Negative Financial Performance Sentiment:
sns.regplot(data=final_analysis, x='Negative_FP_score', y='ret')
plt.show()
6. Positive Financial Performance Sentiment:
sns.regplot(data=final_analysis, x='Positive_FP_score', y='ret')
plt.show()
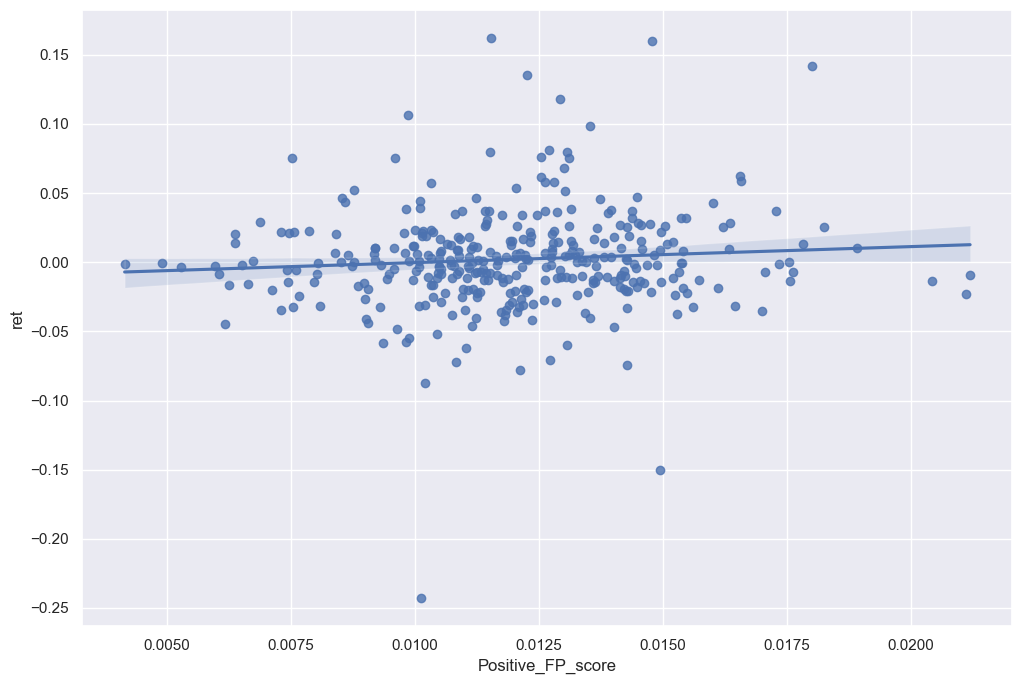
As better displayed in the graphs above, there’s a slight positive trend within the data frames but the correlation isn’t high enough to require further investigation within the topics. However when looking at the sentiment scores in comparison to financial ratios there are some noticeable trends.
sns.regplot(data=final_analysis, x='Positive_RD_score', y='cash_a')
plt.show()
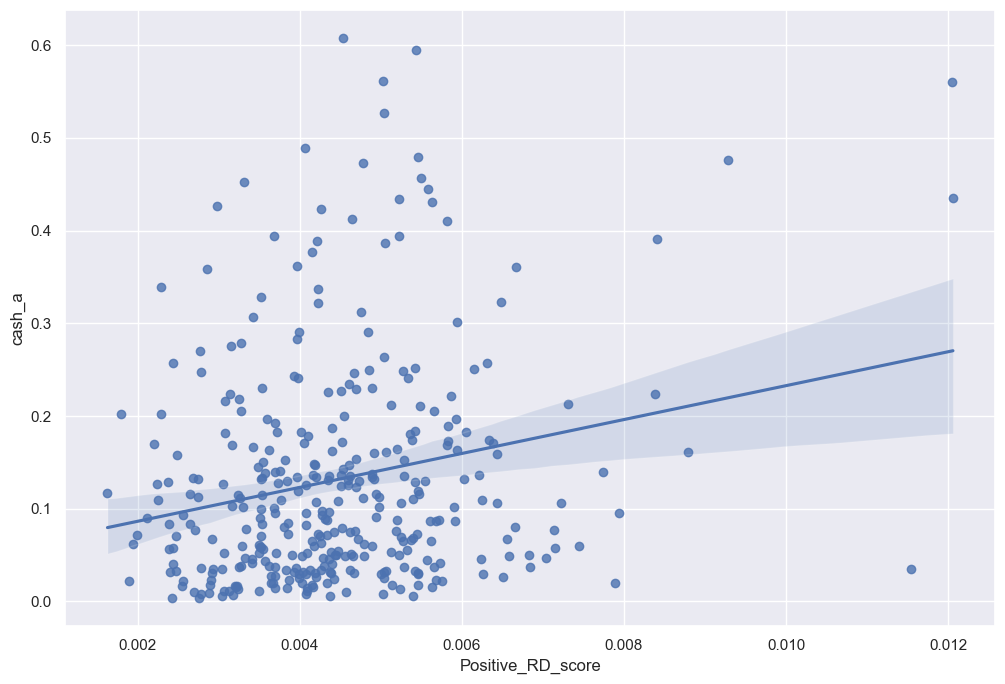
A great example would be in the above graph. A 10-K ridden with positive R&D sentiments tended to have a higher cash per asset ratio. With a noticeably positive regression line, it’s hard not to notice the importance of good quality R&D to a companies assets.
sns.regplot(data=final_analysis, x='Positive_SC_score', y='prof_a')
plt.show()
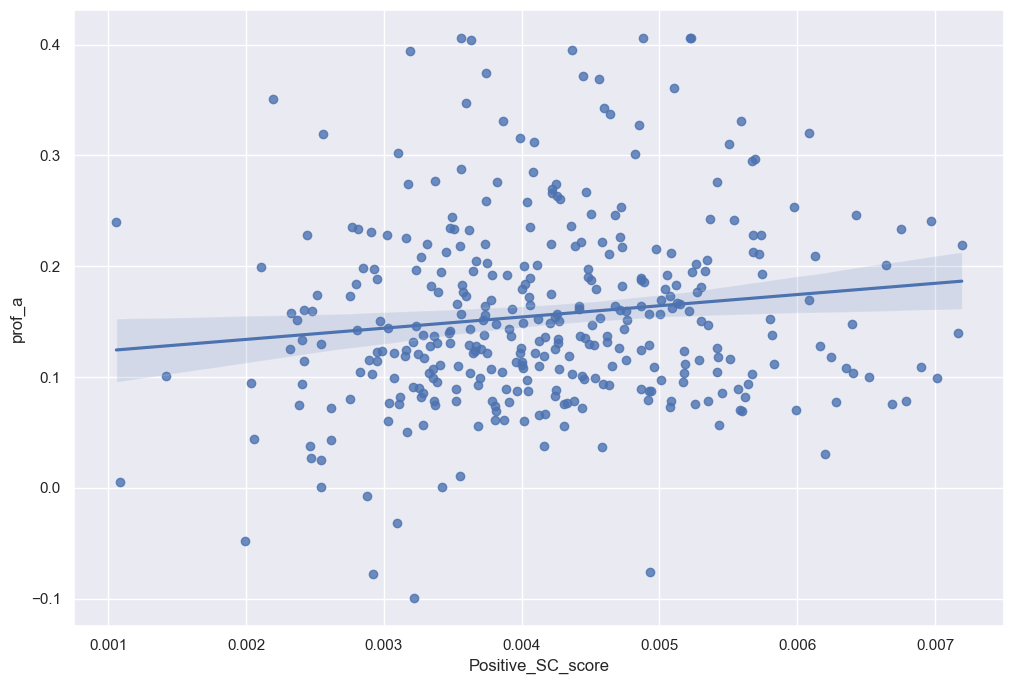
One last great example I found for this topic is in the above graph. Whereas there was no correlation between returns and a positive supply chain sentiment. I noticed there was a positive trend between profit per asset and 10-K’s that displayed a positive sentiment towards their supply chain. As supply chain costs and obstacles decrease and the business continues to thrive within its supply chain function, it makes sense that profitability would have a moderately positive correlation with firms that have positive sentiment towards supply chain displayed in their 10-K.
Topic 4:
However when looking at the 3 contextual sentiment measures in comparison with the return variable, there isn’t a real difference in the sign and magnitude. I believe I made a comprehensive list to detect the contextual sentiment of the 10-K. However looking at the graphs in regards to the return, I can tell that companies try to disguise the sentiment of their 10-K if it evokes a negative sentiment. That’s why hardly any of my negative contextual sentiments have a regression higher than 0. Whereas, the positive contextual sentiment variables seem to have a slight positive correlation in regards to the return variable.